已修改
参考HTTP 协议入门 - 阮一峰的网络日志
HTTP 协议是互联网的基础协议,也是网页开发的必备知识,最新版本 HTTP/2 更是让它成为技术热点。
HTTP/0.9
HTTP 是基于 TCP/IP 协议的应用层协议。它不涉及数据包(packet)传输,主要规定了客户端和服务器之间的通信格式,默认使用80端口。
最早版本是1991年发布的0.9版。该版本极其简单,只有一个命令GET。
上面命令表示,TCP 连接(connection)建立后,客户端向服务器请求(request)网页index.html。
协议规定,服务器只能回应HTML格式的字符串,不能回应别的格式。
服务器发送完毕,就关闭TCP连接。
HTTP/1.0
简介
1996年5月,HTTP/1.0 版本发布,内容大大增加。首先,任何格式的内容都可以发送。这使得互联网不仅可以传输文字,还能传输图像、视频、二进制文件。这为互联网的大发展奠定了基础。
除了GET命令,还引入了POST命令和HEAD命令,丰富了浏览器与服务器的互动手段。
HTTP请求和回应的格式也变了。除了数据部分,每次通信都必须包括头信息(HTTP header),用来描述一些元数据。
其他的新增功能还包括状态码(status code)、多字符集支持、多部分发送(multi-part type)、权限(authorization)、缓存(cache)、内容编码(content encoding)等。
请求格式
下面是一个1.0版的HTTP请求的例子。
第一行是请求命令,必须在尾部添加协议版本(HTTP/1.0)。后面就是多行头信息,描述客户端的情况。
回应格式
服务器的回应如下。
回应的格式是”头信息 + 一个空行( \ r \ n) + 数据”。其中,第一行是”协议版本 + 状态码(status code) + 状态描述”。
Content-Type 字段
关于字符的编码,1.0版规定,头信息必须是 ASCII 码,后面的数据可以是任何格式。因此,服务器回应的时候,必须告诉客户端,数据是什么格式,这就是Content-Type字段的作用。
这些数据类型总称为MIME type,每个值包括一级类型和二级类型,之间用斜杠分隔。除了预定义的类型,厂商也可以自定义类型。
上面的类型表明,发送的是Debian系统的二进制数据包。
MIME type还可以在尾部使用分号,添加参数。
上面的类型表明,发送的是网页,而且编码是UTF-8。
客户端请求的时候,可以使用Accept字段声明自己可以接受哪些数据格式。
上面代码中,客户端声明自己可以接受任何格式的数据。
MIME type不仅用在HTTP协议,还可以用在其他地方,比如HTML网页。
Content-Encoding 字段
由于发送的数据可以是任何格式,因此可以把数据压缩后再发送。Content-Encoding字段说明数据的压缩方法。
客户端在请求时,用Accept-Encoding字段说明自己可以接受哪些压缩方法。
缺点
HTTP/1.0 版的主要缺点是,每个TCP连接只能发送一个请求。发送数据完毕,连接就关闭,如果还要请求其他资源,就必须再新建一个连接。
TCP连接的新建成本很高,因为需要客户端和服务器三次握手,并且开始时发送速率较慢(slow start)。所以,HTTP 1.0版本的性能比较差。随着网页加载的外部资源越来越多,这个问题就愈发突出了。
为了解决这个问题,有些浏览器在请求时,用了一个非标准的Connection字段。
这个字段要求服务器不要关闭TCP连接,以便其他请求复用。服务器同样回应这个字段。
一个可以复用的TCP连接就建立了,直到客户端或服务器主动关闭连接。但是,这不是标准字段,不同实现的行为可能不一致,因此不是根本的解决办法。
HTTP/1.1
1997年1月,HTTP/1.1 版本发布,只比 1.0 版本晚了半年。它进一步完善了 HTTP 协议,一直用到了20年后的今天,直到现在还是最流行的版本。
持久连接
1.1 版的最大变化,就是引入了持久连接(persistent connection),即TCP连接默认不关闭,可以被多个请求复用,不用声明Connection: keep-alive。
客户端和服务器发现对方一段时间没有活动,就可以主动关闭连接。不过,规范的做法是,客户端在最后一个请求时,发送Connection: close,明确要求服务器关闭TCP连接。
管道机制
1.1 版还引入了管道机制(pipelining),即在同一个TCP连接里面,客户端可以同时发送多个请求。这样就进一步改进了HTTP协议的效率。
举例来说,客户端需要请求两个资源。以前的做法是,在同一个TCP连接里面,先发送A请求,然后等待服务器做出回应,收到后再发出B请求。管道机制则是允许浏览器同时发出A请求和B请求,但是服务器还是按照顺序,先回应A请求,完成后再回应B请求。
Content-Length 字段
一个TCP连接现在可以传送多个回应,势必就要有一种机制,区分数据包是属于哪一个回应的。这就是Content-length字段的作用,声明本次回应的数据长度。
上面代码告诉浏览器,本次回应的长度是3495个字节,后面的字节就属于下一个回应了。
在1.0版中,Content-Length字段不是必需的,因为浏览器发现服务器关闭了TCP连接,就表明收到的数据包已经全了。
分块传输编码
使用Content-Length字段的前提条件是,服务器发送回应之前,必须知道回应的数据长度。
对于一些很耗时的动态操作来说,这意味着,服务器要等到所有操作完成,才能发送数据,显然这样的效率不高。更好的处理方法是,产生一块数据,就发送一块,采用”流模式”(stream)取代”缓存模式”(buffer)。
因此,1.1版规定可以不使用Content-Length字段,而使用”分块传输编码”(chunked transfer encoding)。只要请求或回应的头信息有Transfer-Encoding字段,就表明回应将由数量未定的数据块组成。
每个非空的数据块之前,会有一个16进制的数值,表示这个块的长度。最后是一个大小为0的块,就表示本次回应的数据发送完了。下面是一个例子。
其他功能
1.1版还新增了许多动词方法:PUT、PATCH、HEAD、 OPTIONS、DELETE。
另外,客户端请求的头信息新增了Host字段,用来指定服务器的域名。
有了Host字段,就可以将请求发往同一台服务器上的不同网站,为虚拟主机的兴起打下了基础。
缺点
虽然1.1版允许复用TCP连接,但是同一个TCP连接里面,所有的数据通信是按次序进行的。服务器只有处理完一个回应,才会进行下一个回应。要是前面的回应特别慢,后面就会有许多请求排队等着。这称为”队头堵塞”(Head-of-line blocking)。
为了避免这个问题,只有两种方法:一是减少请求数,二是同时多开持久连接。这导致了很多的网页优化技巧,比如合并脚本和样式表、将图片嵌入CSS代码、域名分片(domain sharding)等等。如果HTTP协议设计得更好一些,这些额外的工作是可以避免的。
SPDY 协议
2009年,谷歌公开了自行研发的 SPDY 协议,主要解决 HTTP/1.1 效率不高的问题。
这个协议在Chrome浏览器上证明可行以后,就被当作 HTTP/2 的基础,主要特性都在 HTTP/2 之中得到继承。
HTTP/2
2015年,HTTP/2 发布。它不叫 HTTP/2.0,是因为标准委员会不打算再发布子版本了,下一个新版本将是 HTTP/3。
二进制协议
HTTP/1.1 版的头信息肯定是文本(ASCII编码),数据体可以是文本,也可以是二进制。HTTP/2 则是一个彻底的二进制协议,头信息和数据体都是二进制,并且统称为”帧”(frame):头信息帧和数据帧。
二进制协议的一个好处是,可以定义额外的帧。HTTP/2 定义了近十种帧,为将来的高级应用打好了基础。如果使用文本实现这种功能,解析数据将会变得非常麻烦,二进制解析则方便得多。
多工
HTTP/2 复用TCP连接,在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,而且不用按照顺序一一对应,这样就避免了”队头堵塞”。
举例来说,在一个TCP连接里面,服务器同时收到了A请求和B请求,于是先回应A请求,结果发现处理过程非常耗时,于是就发送A请求已经处理好的部分, 接着回应B请求,完成后,再发送A请求剩下的部分。
这样双向的、实时的通信,就叫做多工(Multiplexing)。
数据流
因为 HTTP/2 的数据包是不按顺序发送的,同一个连接里面连续的数据包,可能属于不同的回应。因此,必须要对数据包做标记,指出它属于哪个回应。
HTTP/2 将每个请求或回应的所有数据包,称为一个数据流(stream)。每个数据流都有一个独一无二的编号。数据包发送的时候,都必须标记数据流ID,用来区分它属于哪个数据流。另外还规定,客户端发出的数据流,ID一律为奇数,服务器发出的,ID为偶数。
数据流发送到一半的时候,客户端和服务器都可以发送信号(RST_STREAM帧),取消这个数据流。1.1版取消数据流的唯一方法,就是关闭TCP连接。这就是说,HTTP/2 可以取消某一次请求,同时保证TCP连接还打开着,可以被其他请求使用。
客户端还可以指定数据流的优先级。优先级越高,服务器就会越早回应。
头信息压缩
HTTP 协议不带有状态,每次请求都必须附上所有信息。所以,请求的很多字段都是重复的,比如Cookie和User Agent,一模一样的内容,每次请求都必须附带,这会浪费很多带宽,也影响速度。
HTTP/2 对这一点做了优化,引入了头信息压缩机制(header compression)。一方面,头信息使用gzip或compress压缩后再发送;另一方面,客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。
服务器推送
HTTP/2 允许服务器未经请求,主动向客户端发送资源,这叫做服务器推送(server push)。
常见场景是客户端请求一个网页,这个网页里面包含很多静态资源。正常情况下,客户端必须收到网页后,解析HTML源码,发现有静态资源,再发出静态资源请求。其实,服务器可以预期到客户端请求网页后,很可能会再请求静态资源,所以就主动把这些静态资源随着网页一起发给客户端了。
HTTPS
HTTPS(全称:Hyper Text Transfer Protocol over Secure Socket Layer 或 Hypertext Transfer Protocol Secure,超文本传输安全协议),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。
SSL/TLS协议运行机制的概述
互联网的通信安全,建立在SSL/TLS协议之上。
不使用SSL/TLS的HTTP通信,就是不加密的通信。所有信息明文传播,带来了三大风险。
SSL/TLS协议是为了解决这三大风险而设计的,希望达到:
互联网是开放环境,通信双方都是未知身份,这为协议的设计带来了很大的难度。而且,协议还必须能够经受所有匪夷所思的攻击,这使得SSL/TLS协议变得异常复杂。
SSL/TLS协议的基本思路是采用公钥加密法,也就是说,客户端先向服务器端索要公钥,然后用公钥加密信息,服务器收到密文后,用自己的私钥解密。
如何保证公钥不被篡改?
解决方法:将公钥放在数字证书中。只要证书是可信的,公钥就是可信的。
公钥加密计算量太大,如何减少耗用的时间?
解决方法:每一次对话(session),客户端和服务器端都生成一个”对话密钥”(session key),用它来加密信息。由于”对话密钥”是对称加密,所以运算速度非常快,而服务器公钥只用于加密”对话密钥”本身,这样就减少了加密运算的消耗时间。
因此,SSL/TLS协议的基本过程是这样的:
上面过程的前两步,又称为”握手阶段”(handshake)。
握手阶段的详细过程
“握手阶段”涉及四次通信,我们一个个来看。需要注意的是,”握手阶段”的所有通信都是明文的。
第一步,客户端(通常是浏览器)先向服务器发出加密通信的请求,这被叫做ClientHello请求。在这一步,客户端主要向服务器提供以下信息。
这里需要注意的是,客户端发送的信息之中不包括服务器的域名。也就是说,理论上服务器只能包含一个网站,否则会分不清应该向客户端提供哪一个网站的数字证书。这就是为什么通常一台服务器只能有一张数字证书的原因。
对于虚拟主机的用户来说,这当然很不方便。2006年,TLS协议加入了一个Server Name Indication扩展,允许客户端向服务器提供它所请求的域名。
第二步,服务器收到客户端请求后,向客户端发出回应,这叫做SeverHello。
除了上面这些信息,如果服务器需要确认客户端的身份,就会再包含一项请求,要求客户端提供”客户端证书”。比如,金融机构往往只允许认证客户连入自己的网络,就会向正式客户提供USB密钥,里面就包含了一张客户端证书。
第三步,客户端回应。客户端收到服务器回应以后,首先验证服务器证书。如果证书不是可信机构颁布、或者证书中的域名与实际域名不一致、或者证书已经过期,就会向访问者显示一个警告,由其选择是否还要继续通信。
如果证书没有问题,客户端就会从证书中取出服务器的公钥。然后,向服务器发送下面三项信息。
上面第一项的随机数,是整个握手阶段出现的第三个随机数,又称”pre-master key”。有了它以后,客户端和服务器就同时有了三个随机数,接着双方就用事先商定的加密方法,各自生成本次会话所用的同一把”会话密钥”。
至于为什么一定要用三个随机数,来生成”会话密钥”
此外,如果前一步,服务器要求客户端证书,客户端会在这一步发送证书及相关信息。
第四步,服务器的最后回应,服务器收到客户端的第三个随机数pre-master key之后,计算生成本次会话所用的”会话密钥”。然后,向客户端最后发送下面信息。
至此,整个握手阶段全部结束。接下来,客户端与服务器进入加密通信,就完全是使用普通的HTTP协议,只不过用”会话密钥”加密内容。
HTTPS 要比 HTTP 多用多少服务器资源?里面还有关于SSL握手的各步需要的原因以及解释
https://www.zhihu.com/question/21518760/answer/19698894
码出高效HTTPS
对称加密算法,比如DES。
访问一个HTTPS的网站流程如下:
- 浏览器向服务器发送请求,请求中包括浏览器支持的协议,并附带一个随机数。
- 服务器收到请求后,选择某种非对称加密算法,把数字证书签名公钥、身份信息发送给浏览器,同时也附带一个随机数。
- 浏览器收到后,验证证书的真实性,用服务器的公钥发送握手信息给服务器。
- 服务器解密后,使用之前的随机数计算出一个对称加密的秘钥,以此作为加密信息并发送。
- 后续所有的信息发送都是以对称加密方式进行的
TLS和SSL的区别。TLS可以理解成SSL协议3.0版本的升级,所以TLS的1.0版本也被标识为SSL3.1版本。但对于大的协议栈而言,SSL和TLS并没有太大的区别,因此在Wireshark里,分层依然用的是安全套接字(SSL) 标识。
在整个HTTPS的传输过程中,主要分两个部分:首先是HTTPS的握手,然后是数据的传输。前者是建立一个HTTPS的通道,并确定连接使用的加密套件及数据传输使用的秘钥。而后者主要使用秘钥对数据加密并传输。
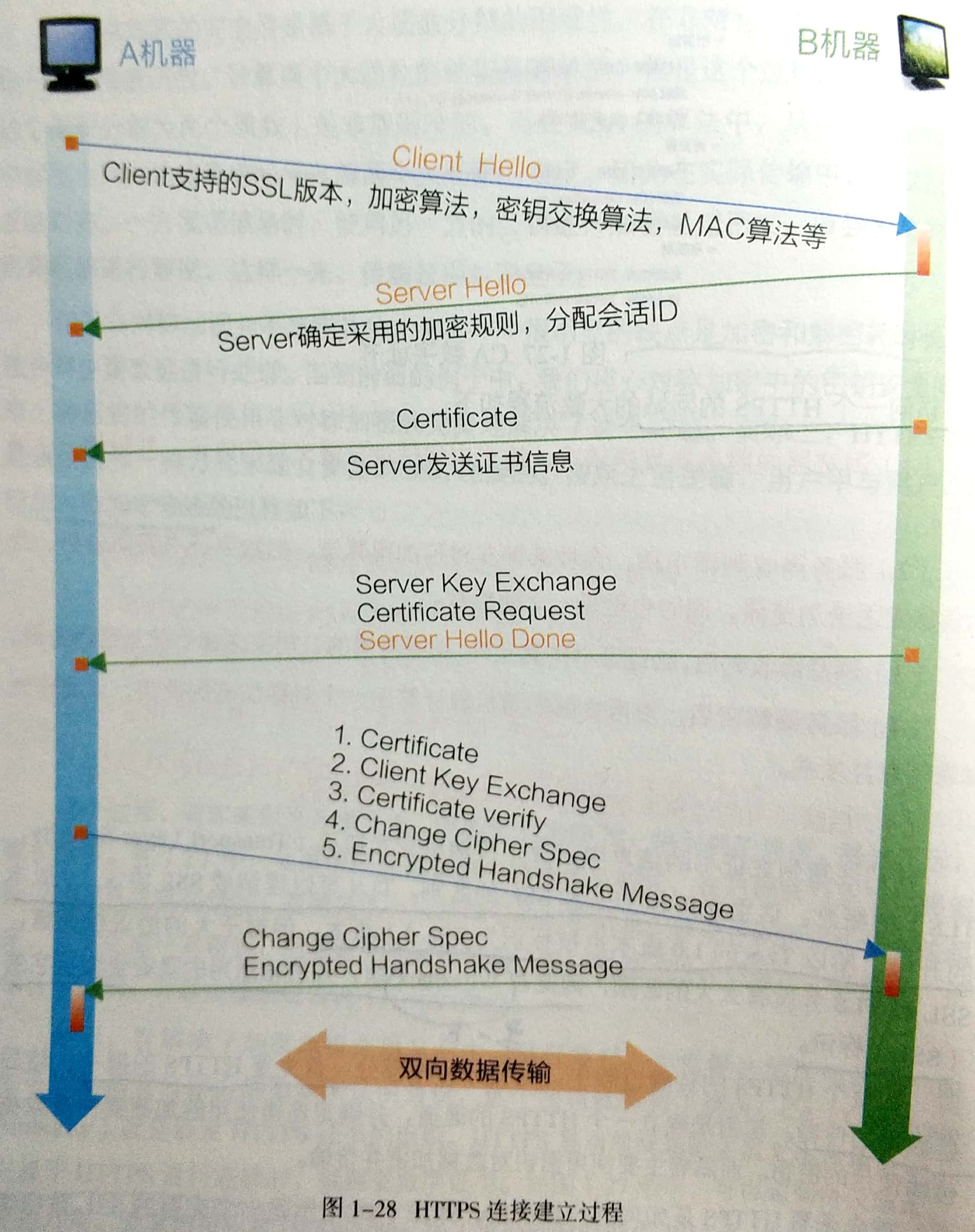
第一,客户端发送了一个Client Hello协议的请求:在Client Hello中最重要的信息是Cipher Suites字段,这里客户端会告诉服务端自己支持哪些加密的套件。
第二,服务端在收到客户端发来的Client Hello的请求后,会返回一系列的协议数据,并以一个没有数据内容的Server Hello Done作为结束。这些协议数据有的是单独发送,有的是合并发送。这里解释几个比较重要的协议。
(1)Server Hello协议。主要告知客户端后续协议中要使用的TLS协议版本,这个版本主要和客户端与服务器端支持的最高版本有关。并为本次连接分配一个会话ID(Session ID)。此外,还会确认后续采用的加密套件(Cipher Suite),比如加密套件为TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256。该加密套件的基本含义为:使用非对称协议加密(RSA)进行对称协议加密(AES)密钥的加密,并使用对称加密协议(AES)进行信息的加密。
(2)Certificate协议。主要传输服务端的证书内容。
(3)Server Key Exchange。如果在Certificate协议中未给出客户端足够的信息,则会在Server Key Exchange进行补充。比如在连接中Certificate未给出证书的公钥(Public Key),这个公钥的信息将会通过Server Key Exchange送给客户端。
(4)Certificate Request。这个协议是一个可选项,当服务端需要对客户端进行证书验证时,才会向客户端发送一个证书请求(Certificate Request)。
(5)最后以Server Hello Done作为结束信息,告知客户端整个Server Hello过程结束。
第三,客户端在收到服务端的握手信息后,根据服务端的请求,也会发送一系列的协议。
(1)Certificate。可选项。上文中服务端发送了Certificate Request需要对客户端进行证书验证,所以客户端要发送自己的证书信息。
(2)Client Key Exchange。它与上文中Server Key Exchange类似,是对客户端Certificate信息的补充,在本次请求中同样是补充了客户端证书的公钥信息。
(3)Certification Verity。对服务端发送的证书信息进行确认。
(4)Change Cipher Spec。该协议不同于其他握手协议(Handshake Protocol),而是作为一个独立协议告知服务端,客户端已经接受之前服务端确认的加密套件,并会在后续通信中使用该加密套件进行加密。
(5)Encrypted Handshake Message。用于客户端给服务端加密套件加密一段Finish的数据,用以验证这条建立起来的加解密通道的正确性。
第四,服务端在接受客户端的确认信息及验证信息后,会对客户端发送的数据进行确认,这里也分为几个协议进行回复。
(1)Change Cipher Spec。通过使用私钥对客户端发送的数据进行解密,并告知后续将使用协商好的加密套件进行加密传输数据。
(2)Encrypted Handshake Message。与客户端的操作相同,发送一段Finish的加密数据验证加密通道的正确性。
最后,如果客户端和服务端都确认加解密无误后,各自按照之前约定的Session Secret对Application Data进行加密传输。
解析HTTP协议六种请求方法
Get
GET可以说是最常见的了,它本质就是发送一个请求来取得服务器上的某一资源。资源通过一组HTTP头和呈现据(如HTML文本,或者图片或者视频等)返回给客户端。GET请求中,永远不会包含呈现数据。
POST
向服务器提交数据。这个方法用途广泛,几乎目前所有的提交操作都是靠这个完成。
HEAD
HEAD和GET本质是一样的,区别在于HEAD不含有呈现数据,而仅仅是HTTP头信息。有的人可能觉得这个方法没什么用,其实不是这样的。想象一个业务情景:欲判断某个资源是否存在,我们通常使用GET,但这里用HEAD则意义更加明确。
DELETE
删除某一个资源。基本上这个也很少见,不过还是有一些地方比如amazon的S3云服务里面就用的这个方法来删除资源。
PUT
这个方法比较少见。HTML表单也不支持这个。本质上来讲, PUT和POST极为相似,都是向服务器发送数据,但它们之间有一个重要区别,PUT通常指定了资源的存放位置,而POST则没有,POST的数据存放位置由服务器自己决定。
OPTIONS
这个方法很有趣,但极少使用。它用于获取当前URL所支持的方法。若请求成功,则它会在HTTP头中包含一个名为“Allow”的头,值是所支持的方法,如“GET, POST”。
REST
URL定位资源,用HTTP动词(GET,POST,DELETE,DETC)描述操作。
增加一个朋友,uri: generalcode.cn/v1/friends 接口类型:POST
删除一个朋友,uri: generalcode.cn/va/friends 接口类型:DELETE
修改一个朋友,uri: generalcode.cn/va/friends 接口类型:PUT
查找朋友,uri: generalcode.cn/va/friends 接口类型:GET
上面我们定义的四个接口就是符合REST协议的,请注意,这几个接口都没有动词,只有名词friends,都是通过Http请求的接口类型来判断是什么业务操作。
GET和POST的区别
最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数。GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
GET和POST本质上就是TCP链接,并无差别。但是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。 对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
因为POST需要两步,时间上消耗的要多一点,看起来GET比POST更有效。因此Yahoo团队有推荐用GET替换POST来优化网站性能。但这是一个坑!跳入需谨慎。为什么?
- GET与POST都有自己的语义,不能随便混用。
- 据研究,在网络环境好的情况下,发一次包的时间和发两次包的时间差别基本可以无视。而在网络环境差的情况下,两次包的TCP在验证数据包完整性上,有非常大的优点。
- 并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次。
HTTP中Cookie
Cookie总是保存在客户端中,按在客户端中的存储位置,可分为内存Cookie和硬盘Cookie。内存Cookie由浏览器维护,保存在内存中,浏览器关闭后就消失了,其存在时间是短暂的。硬盘Cookie保存在硬盘里,有一个过期时间,除非用户手工清理或到了过期时间,硬盘Cookie不会被删除,其存在时间是长期的。所以,按存在时间,可分为非持久Cookie和持久Cookie。
cookie存在哪
Cookie是存在硬盘上, IE存cookie的地方和Firefox存cookie的地方不一样。 不同的操作系统也可能存cookie的地方不一样。不同的浏览器会在各自的独立空间存放Cookie, 互不干涉。不同的网站会有不同的cookie文件。
浏览器把cookie通过HTTP Request 中的“Cookie: header”发送给Web服务器。
Web服务器通过HTTP Response中的”Set-Cookie: header”把cookie发送给浏览器。
网站自动登陆的原理
以”博客园自动登陆“的例子,来说明cookie是如何传递的。大家知道博客园是可以自动登陆的。假如我已经在登陆页面输入了用户名,密码,选择了保存密码,登陆。
下次访问博客园流程如下。
- 用户打开IE浏览器,在地址栏上输入www.cnblogs.com.
- IE首先会在硬盘中查找关于cnblogs.com的cookie. 然后把cookie放到HTTP Request中,再把Request发给Web服务器。
- Web服务器返回博客园首页(你会看到你已经登陆了)。
截获Cookie,冒充别人身份
通过上面这个例子,可以看到cookie是很重要的,识别是否是登陆用户,就是通过cookie。 假如截获了别人的cookie是否可以冒充他人的身份登陆呢。 当然可以, 这就是一种黑客技术叫Cookie欺骗。利用Cookie 欺骗, 不需要知道用户名密码。就可以直接登录,使用别人的账户做坏事。
有两种方法可以截获他人的cookie
- 通过XSS脚步攻击, 获取他人的cookie.
- 想办法获取别人电脑上保存的cookie文件(这个比较难)
拿到cookie后,就可以冒充别人的身份了。
cookie和文件缓存,这两个完全是不一样的东西。唯一的相同之处可能是它们俩都存在硬盘上,而且是存在同一个文件夹下。Cookies是当你浏览某网站时,由Web服务器置于你硬盘上的一个非常小的文本文件,它可以记录你的用户ID、密码、浏览过的网页、停留的时间等信息。
HTTP报文
分为请求报文和响应报文。